Sección 1: La Sombra del Progreso: La Creciente Deuda Ambiental de la Inteligencia Artificial
La inteligencia artificial (IA), en su actual cénit de desarrollo, se encuentra en una encrucijada que definirá su futuro. Su avance, una marcha exponencial hacia modelos de una escala y complejidad antes inimaginables, ha desvelado capacidades que transforman los cimientos de nuestra sociedad. Sin embargo, bajo el deslumbrante fulgor de este progreso, se proyecta una sombra cada vez más extensa: una deuda computacional, financiera y, sobre todo, ambiental, que amenaza con volverse insostenible. En este contexto crítico, el marco de Topographical Sparse Mapping (TSM) y su refinamiento, ETSM, no emergen como una mera optimización, sino como una respuesta fundamental a este desafío existencial. Proponen un nuevo paradigma de eficiencia que no busca su inspiración en la fuerza bruta del silicio, sino en la obra maestra de la optimización biológica: el cerebro humano.
El Paradigma de la Escala: El Crecimiento Exponencial de los Modelos de IA
Durante la última década, la búsqueda de un rendimiento sobrehumano en tareas complejas ha estado gobernada por una única máxima: la escala. Los modelos de aprendizaje profundo han crecido de forma desmedida en tamaño y número de parámetros, una estrategia que, si bien ha cosechado resultados asombrosos, ha alcanzado un punto de rendimientos decrecientes y costes prohibitivos. La Figura 1 del estudio seminal sobre TSM traza esta trayectoria con una claridad elocuente, mostrando un ascenso casi vertical en el número de parámetros, que han pasado de millones a cientos de miles de millones en un lapso brevísimo.
Este gigantismo computacional se traduce en costes que desafían la razón. El entrenamiento de estos colosos digitales exige una inversión financiera masiva. Se estima que el coste de entrenar a GPT-3 osciló entre 4.6 y 12 millones de dólares, mientras que su sucesor, GPT-4, escaló hasta los 78 millones. Las proyecciones para futuros modelos ya superan el umbral de los mil millones de dólares, erigiendo una barrera que confina la vanguardia de la innovación a un selecto grupo de corporaciones con recursos casi ilimitados.
Pero es el coste energético el que revela la faceta más alarmante de esta crisis. El entrenamiento de un único modelo de gran envergadura puede consumir 1,252,000 kWh de electricidad, una cifra que iguala el consumo anual de 125 hogares en Estados Unidos. Esta voracidad energética no solo somete a una presión inmensa a las infraestructuras eléctricas, sino que también se convierte en una fuente significativa de emisiones de gases de efecto invernadero, minando los esfuerzos globales por un futuro sostenible.
La Huella Oculta: Un Impacto Ambiental Multidimensional
El impacto ambiental de la IA es una hidra de múltiples cabezas que va mucho más allá del consumo eléctrico. Un análisis completo de su ciclo de vida desvela una huella ecológica profunda y compleja. Uno de sus costes más insidiosos es el consumo de agua. Los centros de datos, auténticas catedrales del cómputo que albergan los miles de servidores necesarios para dar vida a estos modelos, generan ingentes cantidades de calor. Para disipar esta energía y evitar el colapso, se emplean sistemas de refrigeración que dependen críticamente del agua dulce. Se ha calculado que el entrenamiento de GPT-3 requirió el uso de 700,000 litros de agua, y que una simple conversación con un modelo como ChatGPT, de entre 20 y 50 preguntas, puede consumir hasta medio litro de este preciado recurso. Esta dependencia de un bien cada vez más escaso plantea un dilema ético y de sostenibilidad, especialmente en regiones que ya sufren estrés hídrico.
Además, la huella de carbono de la IA no se limita a su fase operativa. La fabricación del hardware especializado —las unidades de procesamiento gráfico (GPU), CPU y servidores— conlleva un considerable “carbono incorporado”. Este concepto abarca las emisiones generadas por la producción de materiales como el hormigón y el acero para la construcción de los centros de datos, que en conjunto suponen hasta el 8% de las emisiones globales de CO2. A ello se suma la extracción de minerales de tierras raras, como el litio y el cobalto, indispensables para los componentes electrónicos. Esta minería, a menudo concentrada en regiones vulnerables, puede perpetuar la degradación ambiental, la contaminación de acuíferos y la violación de derechos humanos.
La interconexión de estos costes revela una verdad ineludible: la eficiencia computacional es la piedra angular de la sostenibilidad en la IA. La investigación sobre TSM, al buscar una reducción drástica del número de parámetros y de las operaciones de punto flotante (FLOPs), desencadena un efecto dominó de beneficios ambientales. Una menor carga computacional implica un menor consumo eléctrico durante el entrenamiento y la inferencia. Esto, a su vez, reduce la generación de calor y, por ende, la necesidad de una refrigeración intensiva en agua. Un modelo más eficiente puede operar en hardware menos potente, aliviando la presión sobre las cadenas de suministro de minerales y disminuyendo el carbono incorporado en la fabricación de nuevos chips. Por tanto, los avances en eficiencia como los que propone ETSM no son meras optimizaciones técnicas; representan una sanación holística de la huella ambiental de la IA, desde la mina hasta la nube.
El Cambio de Rumbo: De la “IA Roja” a la “IA Verde”
Como respuesta a esta encrucijada, ha surgido en la comunidad científica un movimiento de conciencia: la “Green AI” o IA Verde. Este enfoque propugna un cambio de paradigma, un alejamiento del modelo tradicional —a menudo denominado “Red AI”— que prioriza ciegamente el poder predictivo y la precisión a cualquier coste computacional o ambiental. La Green AI, en cambio, aboga por una ciencia donde el rendimiento y la sostenibilidad no son objetivos contrapuestos, sino facetas de una misma búsqueda de la excelencia.
Los principios de la Green AI son la reducción de la huella de carbono mediante el diseño de algoritmos y arquitecturas más eficientes, la optimización del uso de los recursos, la transparencia en la medición de los costes energéticos y la promoción de una innovación responsable que genere valor con frugalidad. El estudio sobre TSM y ETSM se erige como una contribución capital a este movimiento, ofreciendo una metodología concreta, potente y, sobre todo, biológicamente fundamentada para materializar los ideales de la Green AI.
Más allá de sus virtudes ecológicas, la eficiencia que promueve la Green AI tiene profundas implicaciones para la equidad y la democratización del conocimiento. Los costes prohibitivos del entrenamiento de modelos de vanguardia, como los 78 millones de dólares de GPT-4, crean una barrera infranqueable para la mayoría de las instituciones académicas, startups e investigadores, especialmente en el Sur Global. Esta concentración de poder en unas pocas manos ahoga la diversidad y la innovación. Al reducir drásticamente los requisitos computacionales, marcos como ETSM actúan como una fuerza democratizadora. Hacen que la investigación de vanguardia sea accesible a una comunidad más amplia, fomentando un ecosistema tecnológico más inclusivo y equitativo, un pilar fundamental del movimiento Green AI.
Sección 2: La Lección Magistral de la Naturaleza: Ecos de Cajal en el Sistema Visual de los Vertebrados
Para hallar una solución a la crisis de sostenibilidad de la IA, los artífices del marco TSM no buscaron en los confines del silicio, sino en las profundidades de la biología. El cerebro humano, un órgano de una eficiencia energética que aún hoy nos asombra, no es una simple metáfora para las redes neuronales artificiales; es un plan maestro, un diseño optimizado a lo largo de millones de años de evolución. En su arquitectura resuenan los principios que Santiago Ramón y Cajal, padre de la neurociencia, desveló hace más de un siglo: la neurona como unidad discreta y la conectividad como un tapiz ordenado y no un caos continuo.
Más Allá del Azar: La Doctrina de la Neurona y la Conectividad Dispersa
Una de las premisas más arraigadas en el diseño de redes neuronales artificiales (ANN) es la conectividad densa, donde cada neurona de una capa se enlaza con todas las de la capa siguiente. Esta arquitectura de “todo a todo”, además de ser computacionalmente onerosa, es una quimera biológica. El gran legado de Cajal, su Doctrina de la Neurona, estableció que el sistema nervioso está compuesto por células individuales y discretas, no por una red fusionada. Sus meticulosos dibujos revelaron que las neuronas se comunican por contigüidad, no por continuidad, a través de sinapsis. Esta visión de un sistema compuesto por unidades individuales es la antítesis de la conectividad densa y el fundamento de la dispersión (sparsity) que observamos en el cerebro. La conectividad cerebral no es aleatoria; sigue patrones precisos y estructurados que optimizan el flujo de información y minimizan el gasto energético.
La inspiración principal para el marco TSM emana del sistema visual de los vertebrados, una de las estructuras más elegantemente diseñadas por la naturaleza. Los investigadores se fijaron en los mapas topográficos de la retina, un concepto que Cajal ayudó a elucidar. Estos mapas son representaciones neuronales que preservan las relaciones espaciales del mundo exterior. Es decir, las neuronas que responden a puntos adyacentes en el campo visual también se encuentran físicamente próximas en la corteza cerebral. Este diseño, un eco de la organización lógica que Cajal dibujó, garantiza un procesamiento eficiente y localizado, evitando la redundancia de conectar cada fotorreceptor con cada neurona de procesamiento visual.
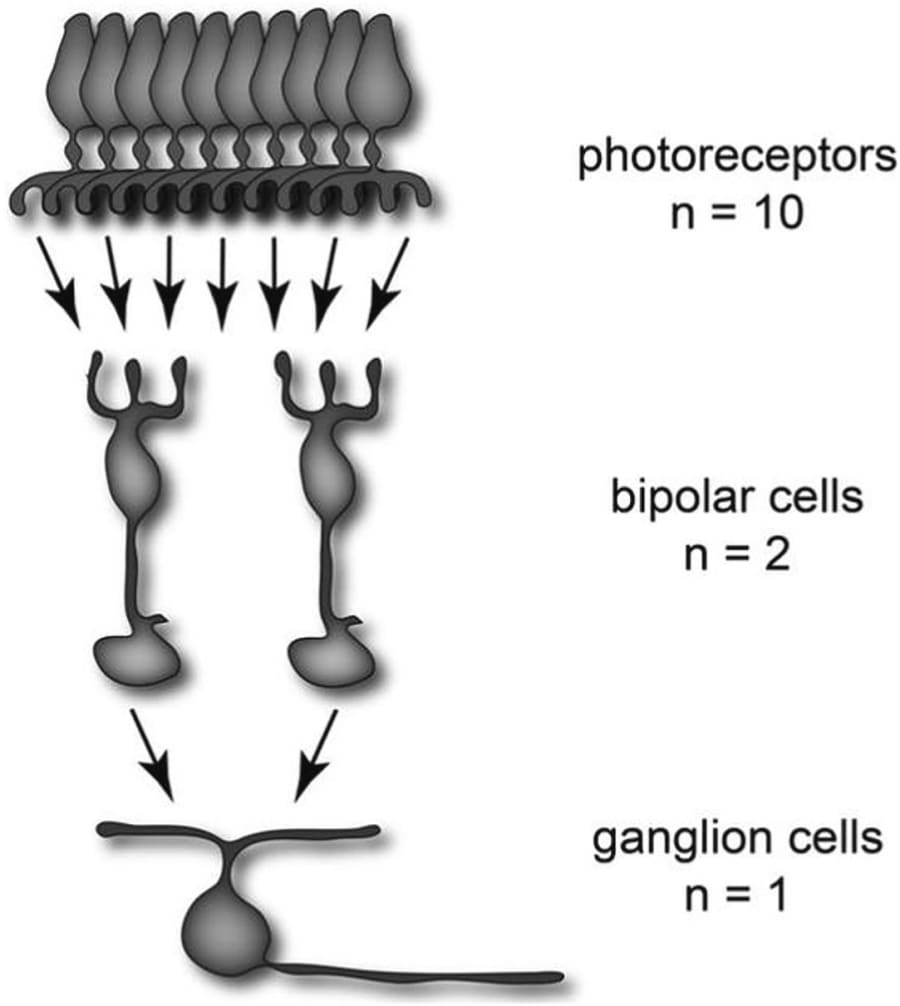
La Arquitectura de la Visión: Retinotopía y Unidades Convergentes
El principio organizativo que subyace a estos mapas se conoce como organización retinotópica: el mapeo ordenado y estructurado de los estímulos visuales desde la retina hasta la corteza visual primaria. Este orden no es un detalle menor; es la clave de la asombrosa eficiencia computacional del cerebro.
Un mecanismo fundamental en esta arquitectura es el de las unidades convergentes. En lugar de que cada célula fotorceptora (cono o bastón) disponga de una línea exclusiva hacia el cerebro, la información se agrupa y comprime en las primeras etapas. El documento de TSM cita un ejemplo elocuente: en la retina periférica, hasta 50 o más fotorreceptores pueden converger y enviar sus señales a una única célula bipolar. Esta convergencia masiva es un precedente biológico directo de la capa de entrada dispersa de TSM: un mecanismo que toma una vasta cantidad de características de entrada y las mapea de forma eficiente a una representación más compacta y dispersa.
La Dinámica del Desarrollo: Proliferación y Poda Sináptica
El cerebro no nace con su cableado definitivo. Su desarrollo es un proceso dinámico de dos fases, una danza de creación y refinamiento que inspira directamente el diseño del marco ETSM. Durante las primeras etapas del desarrollo, se produce una masiva y exuberante proliferación de sinapsis, creando una red inicial hiperconectada. Posteriormente, a medida que el cerebro aprende e interactúa con su entorno, tiene lugar un proceso de poda sináptica (synaptic pruning). Las conexiones que se utilizan con frecuencia se fortalecen, mientras que aquellas que son débiles o redundantes se eliminan gradualmente, como un escultor que retira el mármol sobrante para revelar la forma perfecta.
Este proceso de “esculpir” la red a través de la experiencia es extraordinariamente eficiente. Permite al cerebro adaptarse y especializarse, refinando su arquitectura para optimizar el rendimiento. Esta dinámica biológica —un mapeo inicial estructurado seguido de una poda selectiva— proporciona la inspiración directa para el marco ETSM: se comienza con la capa TSM de estructura fija y luego se aplica una poda dinámica basada en la magnitud de los pesos para refinar el resto de la red.
La adopción de estos principios biológicos representa un puente pragmático hacia el futuro de la computación. La literatura sobre Green AI identifica la computación neuromórfica —hardware diseñado para imitar la arquitectura del cerebro— como una solución a largo plazo. Sin embargo, este hardware aún está en desarrollo. El marco TSM/ETSM es una innovación crucial porque es una implementación a nivel de software de estos principios neuromórficos que puede ejecutarse en el hardware convencional (GPU y CPU) de hoy. Permite cosechar los beneficios de eficiencia del diseño inspirado en el cerebro ahora, demostrando que los principios arquitectónicos, y no solo el sustrato físico, son la fuente primordial de la eficiencia cerebral.
Este enfoque es también un rechazo fundamental de la aleatoriedad como punto de partida. Muchos métodos de vanguardia comienzan con una red de conexión aleatoria y luego emplean métricas computacionalmente costosas para buscar una topología dispersa eficiente. El documento de TSM argumenta explícitamente que “conectar neuronas entre sí al azar no es óptimo” y conduce a ineficiencias. La evidencia biológica, desde los tiempos de Cajal, es clara: la conectividad cerebral es el antónimo de la aleatoriedad; es altamente estructurada y determinista. Por tanto, el argumento filosófico central del trabajo es que la estructura es superior al azar. En lugar de gastar vastos recursos para descubrir una buena estructura dispersa desde un estado caótico, es mucho más eficiente imponer una buena estructura, probada por la evolución, desde el principio. Esto constituye un cambio de paradigma fundamental en el diseño de redes dispersas, un retorno a los primeros principios de la neuroanatomía.
Sección 3: Deconstruyendo el Marco: La Arquitectura del Mapeo Topográfico Disperso (TSM) y ETSM
Desde la inspiración biológica hasta la implementación técnica, los marcos TSM y ETSM ofrecen un enfoque elegante y determinista para construir redes neuronales eficientes desde su concepción. Esta sección desglosa la arquitectura de estos algoritmos, explicando cómo se formula el esquema de cableado y cómo opera el mecanismo de poda dinámica para lograr niveles extremos de dispersión sin sacrificar el rendimiento.
La Capa de Entrada TSM: Un Esquema de Cableado Determinista
El núcleo de la innovación de TSM reside en su capa de entrada. En lugar de una conexión densa, TSM implementa una capa dispersa donde el número total de conexiones es exactamente igual al número de características de entrada. Este diseño, de una simplicidad poderosa, garantiza que toda la información de entrada se preserve —ninguna característica se descarta— al tiempo que se reduce drásticamente el número de parámetros en la capa más pesada de la red.
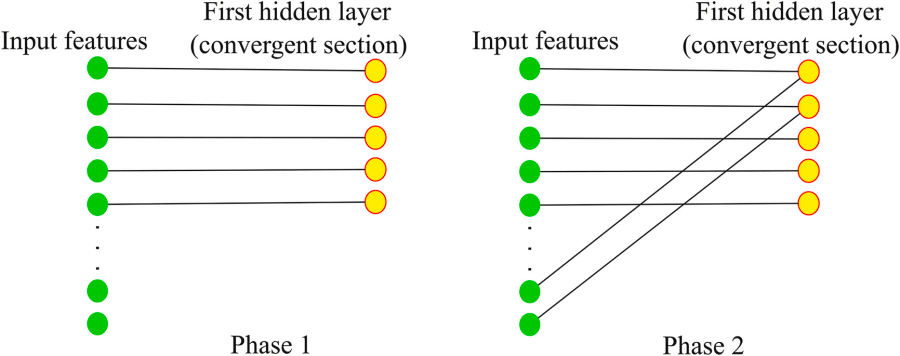
El esquema de cableado que logra esto es un proceso determinista de dos fases, ilustrado con claridad en la Figura 4 del documento de investigación:
-
Fase 1: Cada característica de entrada (presináptica) se conecta secuencialmente a la neurona disponible más cercana en la siguiente capa (postsináptica). Este proceso continúa hasta que cada neurona en la segunda capa ha recibido una conexión.
-
Fase 2: Las características de entrada restantes se conectan siguiendo el mismo patrón cíclico de arriba hacia abajo, enlazándose una por una a las neuronas de la segunda capa hasta que cada característica de entrada ha formado exactamente una sinapsis.
Este enfoque basado en reglas elimina por completo la necesidad de un “espacio de búsqueda” o de complejos algoritmos de optimización para determinar la topología inicial, una de las principales ventajas sobre otros métodos de entrenamiento disperso. La máscara de peso resultante de este proceso es altamente estructurada y predecible, asemejándose a una concatenación de matrices de identidad, como se muestra en la Ecuación 1 del documento.
ETSM Mejorado: De la Semilla Dispersa a la Dispersión en Toda la Red
Mientras que TSM establece una base eficiente en la capa de entrada, el marco ETSM (Enhanced TSM) extiende el principio de dispersión a toda la red, permitiendo al usuario alcanzar un nivel de dispersión global predefinido. El proceso de ETSM es una elegante emulación del desarrollo neuronal:
-
Inicialización: La red se construye con la capa de entrada dispersa de TSM, creando una “semilla” estructuralmente eficiente.
-
Entrenamiento Inicial: La red se entrena durante un breve período, típicamente alrededor del 10% del total de épocas. Esta fase permite que los pesos de las conexiones se ajusten y se estabilicen, revelando su importancia relativa para la tarea en cuestión.
-
Poda Dinámica: Se realiza un único y agresivo paso de poda basada en la magnitud en todas las capas de la red. Se establece un umbral global y todas las conexiones cuyos pesos caen por debajo de este umbral se eliminan permanentemente. Este paso único permite alcanzar el nivel de dispersión deseado (por ejemplo, 98.6%) de manera eficiente.
-
Afinamiento (Fine-Tuning): La red, ahora extremadamente dispersa, continúa su entrenamiento durante las épocas restantes. Esta fase afina los pesos de las conexiones supervivientes, optimizando el rendimiento de la arquitectura final.
Un aspecto crucial que distingue a ETSM de otros algoritmos de entrenamiento disperso dinámico como SET o RigL es la ausencia total de una fase de recrecimiento (regrowth). ETSM no añade nuevas conexiones después de la poda. Este diseño de “podar y afinar” reduce drásticamente la complejidad algorítmica y la sobrecarga computacional, como se visualiza en la Figura 6 del documento.
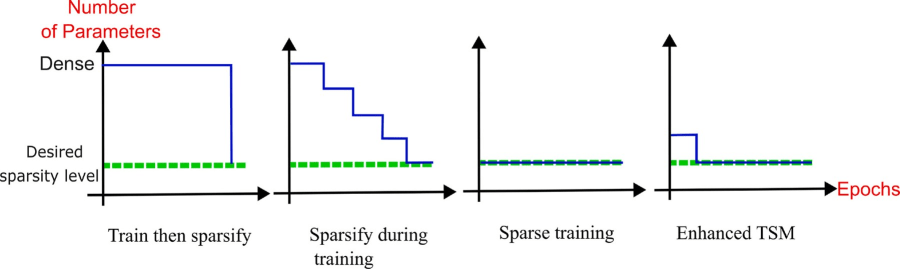
Ventajas Clave del Marco TSM/ETSM
El diseño de TSM/ETSM confiere un conjunto de ventajas significativas que abordan muchas de las deficiencias de los métodos de dispersión existentes. El documento de investigación sintetiza estos beneficios en siete puntos clave:
-
Simplicidad de implementación: El esquema de cableado determinista y la poda de un solo paso son fáciles de implementar.
-
Simplicidad de inicialización: Elimina la necesidad de experimentar con complejas estrategias de inicialización aleatoria.
-
Sin espacio de búsqueda: Evita los costosos cálculos necesarios para buscar una topología óptima.
-
Mejor generalización: Como demuestran los experimentos, la estructura impuesta a menudo conduce a una mayor precisión en datos no vistos.
-
Sin pérdida de información: Todas las características de entrada se conservan en la capa TSM.
-
Indexación más ligera: La estructura regular y la poda única minimizan la sobrecarga de indexación en el hardware.
-
Mejor estabilidad de la red: El entrenamiento es más consistente y menos susceptible a inicializaciones desafortunadas.
El marco ETSM representa una síntesis inteligente de filosofías de dispersión que a menudo compiten entre sí. Combina la dispersión estructurada (en la capa de entrada TSM) para la eficiencia inicial y la preservación de características, con la flexibilidad de la dispersión no estructurada (en la poda por magnitud) para la optimización específica de la tarea. Todo esto se logra dentro de un paradigma de “entrenamiento disperso desde cero” (sparse-from-scratch), que evita el coste prohibitivo de pre-entrenar un modelo denso. Esta combinación híbrida es una razón fundamental de su rendimiento superior.
La ventaja de una “indexación más ligera” es un beneficio práctico de suma importancia para la implementación en hardware real. Las GPU modernas están optimizadas para operaciones con matrices densas. Los patrones de dispersión irregulares y aleatorios generados por muchos otros métodos rompen esta eficiencia, ya que el hardware debe almacenar y buscar los índices de cada peso no nulo, lo que crea una sobrecarga computacional y de memoria significativa. La estructura altamente regular de la capa TSM y el enfoque de “podar una vez” de ETSM minimizan esta sobrecarga. Esto hace que ETSM no solo sea teóricamente eficiente en términos de FLOPs, sino también prácticamente eficiente para su despliegue en las GPU que dominan el panorama de la IA.
Sección 4: Validación Empírica: La Evidencia de un Nuevo Estado del Arte
La validación empírica es el crisol donde las ideas teóricas demuestran su temple. En el caso de TSM y ETSM, los resultados experimentales no solo corroboran las premisas del marco, sino que establecen un nuevo estándar de rendimiento en el campo del entrenamiento disperso. A través de una serie de comparaciones rigurosas, este trabajo aporta la evidencia cuantitativa de una superioridad que redefine la relación entre dispersión, precisión y eficiencia.
Rendimiento de TSM: Superando a los Puntos de Referencia con Mayor Dispersión
El rendimiento del marco base, TSM, se evaluó en comparación con modelos densos y cinco métodos de dispersión de vanguardia (SNIP, RigL, SET, CTREseq y CTREsim). Los resultados, presentados en la Tabla 1 del documento, son particularmente reveladores en los conjuntos de datos más complejos como CIFAR-10 y CIFAR-100.
En el caso de CIFAR-10, TSM no solo iguala, sino que supera la precisión de su contraparte densa (51.42% frente a 51.2%) y de todos los demás métodos dispersos (por ejemplo, SET con 50.6%). Lo más notable es que logra esta hazaña con un nivel de dispersión significativamente mayor (92.6% frente al 85.4% de los competidores), utilizando drásticamente menos parámetros.
El resultado en CIFAR-100 es aún más contundente. TSM alcanza una precisión del 24.43%, superando de manera convincente tanto al modelo denso (23.1%) como al mejor competidor disperso, CTREsim (21.9%). Nuevamente, este rendimiento superior se logra con una mayor dispersión (90.19% frente a 85.46%) y una fracción de los parámetros. En el conjunto de datos MNIST, TSM alcanza una precisión competitiva del 96.83%, aunque este resultado se obtuvo tras eliminar una capa oculta para alcanzar un nivel de dispersión comparable, una limitación arquitectónica que el marco ETSM está diseñado para superar.
Tabla 1: Rendimiento Comparativo de TSM en Conjuntos de Datos Fundamentales
Resultados de precisión en test, dispersión y número de parámetros para TSM en comparación con un modelo denso y métodos de dispersión de vanguardia. Los datos se extraen de la Tabla 1 del estudio original.
Conjunto de DatosMétodoPrecisión en Test (%)****Dispersión (%)****Nº de Parámetros (x10^3)****MNISTDenso97.9 ± 0.0-99.4SNIP97.2 ± 0.181.818.2RigL97.2 ± 0.281.818.2SET97.6 ± 0.181.818.2CTREseq97.7 ± 0.181.818.2CTREsim97.8 ± 0.181.818.2TSM96.83 ± 0.1388.5611.36CIFAR-10Denso51.2 ± 0.5-328.2SNIP49.5 ± 0.785.447.9RigL50.5 ± 0.585.447.9SET50.6 ± 0.585.447.69CTREseq50.1 ± 0.585.447.9CTREsim50.5 ± 0.485.447.9TSM (SGD)51.42 ± 0.2592.624.07CIFAR-100Denso23.1-337.2SNIP20.4 ± 0.385.4649.0RigL21.4 ± 0.485.4649.0SET21.7 ± 0.385.4649.0CTREseq21.8 ± 0.585.4649.0CTREsim21.9 ± 0.485.4649.0TSM (SGD)24.43 ± 0.2690.19****33.07
Rendimiento de ETSM: Dominio en Regímenes de Dispersión Extrema
El marco ETSM fue concebido para explorar los límites de la dispersión, y los resultados de la Tabla 2 del documento demuestran su maestría en este desafiante escenario. Las comparaciones se realizaron contra el mejor método competidor para cada nivel de dispersión específico.
En el régimen de alta dispersión (entre 98.6% y 98.9% de los pesos eliminados), ETSM exhibe una ventaja consistente y a menudo amplia. El caso más destacado es, de nuevo, CIFAR-100, donde con una dispersión del 98.9% (solo un 1.1% de densidad de pesos), ETSM alcanza una precisión del 17.64%. Esto representa una mejora relativa del 20% sobre el competidor más fuerte, SET, que solo alcanza el 14.7%. En CIFAR-10, con el mismo nivel de dispersión, ETSM (49.47%) también supera a SET (48.3%).
La superioridad de ETSM en estos regímenes es estadísticamente significativa. El estudio reporta los resultados de pruebas t, que para el conjunto de datos MNIST en el régimen de alta dispersión arrojan un valor de P-value = 0.0003, indicando una diferencia de una significancia estadística extraordinaria.
Tabla 2: Rendimiento de ETSM en Niveles de Dispersión Extremos y Medios
Comparación de la precisión en test de ETSM frente al mejor método competidor en diferentes niveles de densidad (porcentaje de pesos retenidos). Los datos se extraen de la Tabla 2 del estudio original.
Conjunto de Datos****Nivel de Densidad (%)MétodoPrecisión en Test (%)****Isolet1.5SET89.1 ± 1.2ETSM****91.2 ± 0.27.4SET94.2 ± 0.7ETSM93.4 ± 0.3MNIST1.4CTREseq95.7 ± 0.2ETSM****96.18 ± 0.17CTREsim97.3 ± 0.1ETSM97.25 ± 0.11F-MNIST1.4SET85.8 ± 0.3ETSM****86.1 ± 0.157CTREsim87.5 ± 0.3ETSM87.44 ± 0.12CIFAR-101.1SET48.3 ± 0.5ETSM****49.47 ± 0.135.6CTREsim50.3 ± 0.3ETSM50.89 ± 0.23CIFAR-1001.1SET14.7 ± 0.4ETSM****17.64 ± 0.135.6CTREseq21.1 ± 0.3ETSM****24.05 ± 0.16
Rompiendo el Dogma: La Falsa Dicotomía entre Dispersión y Precisión
La sabiduría convencional en el aprendizaje profundo ha sostenido durante mucho tiempo la existencia de un compromiso ineludible: para aumentar la eficiencia (dispersión), se debe sacrificar la precisión. Los resultados de TSM y ETSM no solo desafían, sino que en muchos casos pulverizan este dogma.
La evidencia más clara de esta ruptura es el rendimiento en CIFAR-100. Un modelo TSM, con un 90.19% de sus conexiones eliminadas, no solo es más eficiente que el modelo denso, sino que es más preciso. Este resultado, que también se observa en comunicados que confirman que los modelos ETSM igualan o superan la precisión de las redes estándar con hasta un 99% de dispersión, es un hallazgo de profunda importancia. Sugiere que la dispersión estructurada e inspirada en la biología no es solo una técnica de compresión, sino también una forma de regularización implícita. Al imponer una estructura eficiente y eliminar conexiones redundantes, el marco parece guiar a la red hacia soluciones que generalizan mejor a datos no vistos, evitando el sobreajuste que puede plagar a los modelos densos sobreparametrizados.
Sección 5: La Revolución de la Eficiencia: Un Salto Cuántico en Ahorro Computacional
Más allá de la precisión, el verdadero impacto de un marco de IA sostenible se mide en su frugalidad. Los resultados del estudio sobre TSM y ETSM revelan una reducción tan drástica en los costes computacionales que solo puede calificarse de revolucionaria. El análisis cuantitativo de la velocidad de convergencia, las operaciones computacionales (FLOPs), el consumo de energía y el uso de memoria demuestra que este enfoque inspirado en el cerebro ofrece un camino viable hacia una IA de alto rendimiento y bajo impacto.
Velocidad de Convergencia: Aprender Mejor y Más Rápido
Uno de los mayores lastres en el desarrollo de la IA es el tiempo de entrenamiento. Los métodos de referencia analizados en el estudio requieren 500 épocas para alcanzar su rendimiento óptimo. En contraste, TSM y ETSM logran resultados superiores en una fracción de ese tiempo. En CIFAR-10, TSM converge en solo 10 a 50 épocas, mientras que en el más complejo CIFAR-100, ETSM alcanza su cénit en 25 a 60 épocas. Esto representa una reducción del tiempo de entrenamiento de entre 10 y 50 veces.
Un experimento comparativo directo con un marco genérico de “Dispersión Durante el Entrenamiento” (SDT) subraya la ventaja de la inicialización topográfica. Como se muestra en la Figura 12 del documento, tras una poda agresiva, el modelo ETSM se recupera y converge en aproximadamente 50 épocas. El modelo SDT, que parte de una arquitectura densa, requiere 175 épocas para alcanzar la convergencia, y aun así finaliza con una precisión significativamente menor. Esto indica que la estructura topográfica inicial no solo es eficiente, sino que dota a la red de una mayor resiliencia y capacidad de adaptación.
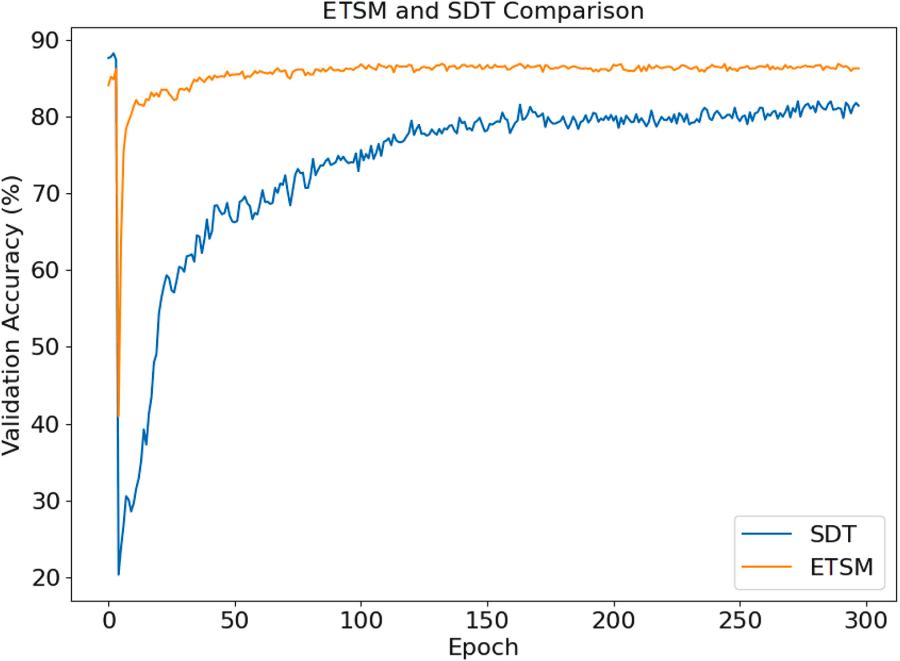
Coste Computacional: Reducción de Órdenes de Magnitud en FLOPs y Energía
El análisis de costes computacionales, detallado en la Tabla 3 del estudio, ofrece las cifras más impactantes sobre la eficiencia de TSM. Para la tarea de clasificación en CIFAR-100, el modelo denso de referencia requiere un total de 3.282 x 10^13 FLOPs para su entrenamiento. En comparación, el modelo TSM (utilizando el optimizador Adam) completa la misma tarea con solo 6.2358 x 10^10 FLOPs. Esto equivale a una reducción al 0.19% del coste computacional del modelo denso.
Esta drástica reducción en las operaciones se traduce directamente en un ahorro energético monumental. El entrenamiento del modelo denso consume un estimado de 9.12 kWh. El modelo TSM, por otro lado, consume una cantidad casi insignificante: 0.000017 kWh, lo que representa el 0.00019% de la energía del modelo de referencia. Estos datos empíricos respaldan las afirmaciones de comunicados de prensa que indican que ETSM consume menos del 1% de la energía de un sistema de IA convencional. Es importante destacar que esta eficiencia se logra sin las sobrecargas computacionales que afectan a otros métodos dispersos, como los cálculos de prominencia (SNIP) o las pasadas de gradiente denso (RigL, CTRE).
Tabla 3: Análisis de Coste Computacional y Energético en CIFAR-100
Comparación de FLOPs totales y consumo de energía (kWh) para TSM frente a un modelo denso y otros métodos de entrenamiento disperso. Los datos se extraen de la Tabla 3 del estudio original.
AlgoritmoFLOPs TotalesSobrecarga AdicionalFLOPs Relativos vs. DensoEnergía (kWh)****Energía Relativa vs. DensoDenso3.282 x 10^13-100%9.12100%SNIP4.923 x 10^12Cálculo de puntuación de prominencia15%1.3715%SET4.923 x 10^12Poda y recrecimiento periódicos15%1.3715%RigL8.205 x 10^12Pasadas de gradiente denso25%2.2825%CTRE8.205 x 10^12Similitud del coseno + exploración topológica aleatoria25%2.2825%TSM (Adam, 10 ep)6.2358 x 10^10Ninguna****0.19%0.0000170.00019%TSM (SGD, 50 ep)3.1179 x 10^11Ninguna0.95%0.0000870.00095%
Huella de Memoria: Habilitando la IA en el Borde (Edge)
La eficiencia de la memoria es un factor crítico, especialmente para el despliegue de modelos de IA en dispositivos con recursos limitados como teléfonos inteligentes o sensores. El análisis de la huella de memoria máxima, presentado en la Tabla 4 del documento, revela otra ventaja clave de ETSM.
En el conjunto de datos CIFAR-100, un modelo denso requiere aproximadamente 1.29 MB para almacenar sus pesos y gradientes. Curiosamente, métodos dispersos como RigL y CTRE, a pesar de tener pocos pesos activos, requieren una memoria máxima de 2.61 MB. Esto se debe a que necesitan mantener temporalmente gradientes densos o estructuras de datos auxiliares, eliminando en la práctica cualquier ventaja de memoria.
En cambio, el uso de memoria de ETSM escala directamente con su nivel de dispersión. Con una dispersión del 98.9% en CIFAR-100, ETSM requiere un pico de memoria de solo 0.07 MB. Esto representa una reducción de aproximadamente 37 veces en comparación con RigL/CTRE y de 18 veces en comparación con el modelo denso. Esta huella de memoria ultraligera es lo que hace factible el despliegue de modelos potentes en el borde de la red (edge computing), abriendo un abanico de nuevas aplicaciones en el mundo real.
Tabla 4: Comparación de la Huella de Memoria Máxima (MB)
Consumo de memoria máximo para modelos densos y dispersos en diferentes conjuntos de datos y niveles de dispersión. Los datos se extraen de la Tabla 4 del estudio original.
**Conjunto de DatosDispersiónMemoria Densa (MB)****SNIP/SET/ETSM (MB)****RigL/CTRE (MB)**MNIST98.6%0.760.020.77MNIST93.0%0.760.060.77Fashion-MNIST98.6%0.760.020.77Fashion-MNIST93.0%0.760.060.77CIFAR-1098.9%1.250.072.54CIFAR-1094.4%1.250.182.54CIFAR-10098.9%1.290.072.61CIFAR-10094.4%1.290.182.61
Sección 6: El Poder del Orden: La Victoria de la Estructura sobre el Azar
Una pregunta fundamental que emana del éxito del marco TSM es: ¿se deben sus ventajas simplemente a la dispersión, o es la estructura topográfica específica, ese eco del orden Cajaniano, la que marca la diferencia? Para responder a esta cuestión, los investigadores llevaron a cabo un experimento de ablación crucial, diseñado para aislar el efecto del patrón de conectividad. Los resultados, detallados en la sección 4.6 del documento, proporcionan una prueba definitiva de que el orden y la estructura inspirados en la biología son el ingrediente activo clave, superando de manera concluyente a la dispersión aleatoria.
Aislamiento de la Variable: Topografía frente a Aleatoriedad
El diseño experimental fue meticuloso en su objetivo de aislar la variable del patrón de conectividad. Se comparó el rendimiento del diseño topográfico de TSM con dos arquitecturas alternativas que mantenían exactamente el mismo número total de conexiones (es decir, el mismo nivel de dispersión):
-
Dispersión aleatoria globalmente restringida: Las conexiones se distribuyen completamente al azar entre la capa de entrada y la primera capa oculta. En este escenario, algunas características de entrada pueden quedar sin conexión.
-
Dispersión aleatoria localmente restringida: Se impone una restricción adicional: cada característica de entrada debe tener exactamente una conexión, garantizando que no se pierda información. Sin embargo, la neurona de destino para cada conexión se elige al azar, en lugar de seguir el patrón secuencial y ordenado de TSM.
Al mantener constantes todos los demás hiperparámetros, esta comparación permite atribuir cualquier diferencia de rendimiento directamente a la naturaleza del patrón de conectividad: ordenado y topográfico frente a desordenado y aleatorio.
Superioridad Cuantitativa en Precisión y Estabilidad
Los resultados del experimento, entrenado en el desafiante conjunto de datos CIFAR-100, fueron inequívocos. El análisis de los diagramas de caja (Figura 14) y las pruebas estadísticas (Tablas 5 y 6) del documento revelan una doble victoria para el modelo topográfico.
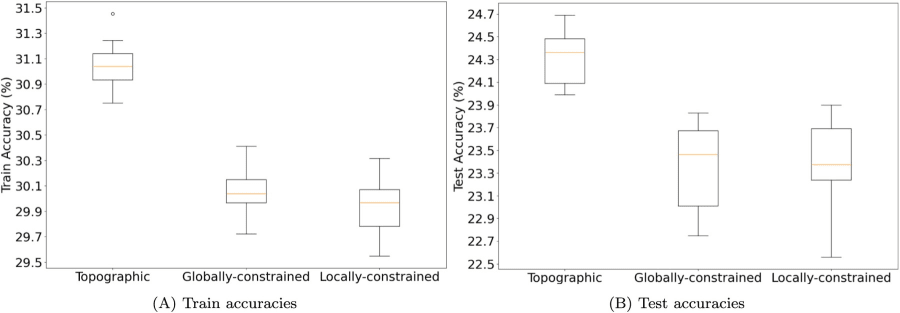
Tabla 5: Análisis Estadístico de las Precisiones en Entrenamiento y Test
Análisis de la tendencia central y la variabilidad para los tres modelos, con N=30 para cada grupo. Los datos se extraen de la Tabla 5 del estudio original.
ModeloPrecisión Media (Entrenamiento)Desv. Est. (Entrenamiento)Precisión Media (Test)Desv. Est. (Test)Globalmente Restringido30.060.20523.350.379Localmente Restringido29.950.20723.420.373Topográfico31.050.19924.320.257
Tabla 6: Pruebas T para las Diferencias entre Precisiones
Resultados de las pruebas t que comparan el modelo topográfico con los diseños con conectividad aleatoria. Los datos se extraen de la Tabla 6 del estudio original.
**Comparación****Diferencia en Precisión (Entrenamiento)****Diferencia en Precisión (Test)**Topográfico vs. Globalmente RestringidoEstadísticamente SignificativaEstadísticamente SignificativaTopográfico vs. Localmente RestringidoEstadísticamente SignificativaEstadísticamente Significativa
En primer lugar, en términos de precisión, el modelo topográfico demostró una clara superioridad. La mediana de la precisión en el conjunto de test para el modelo topográfico fue entre un 3.8% y un 4.2% más alta que la de los dos modelos con conectividad aleatoria. Como se visualiza en los diagramas de caja, no hay solapamiento entre el rango de rendimiento del modelo topográfico y los de los modelos aleatorios, lo que indica una ventaja consistente y robusta.
En segundo lugar, y quizás de manera aún más significativa, el modelo topográfico exhibió una estabilidad de entrenamiento muy superior. La variabilidad en los resultados de precisión (medida por el rango de los diagramas de caja y la desviación estándar) fue drásticamente menor para el diseño topográfico. El estudio reporta que la variabilidad fue entre un 50% y un 90% menor en comparación con los diseños aleatorios. Esto significa que el modelo topográfico no solo alcanza un mejor rendimiento, sino que lo hace de manera mucho más fiable y consistente, siendo menos susceptible a los caprichos de la inicialización aleatoria de los pesos.
El análisis de la diferencia en las curvas de aprendizaje (Figura 15) refuerza esta conclusión, mostrando que la ventaja de rendimiento del modelo topográfico sobre los modelos aleatorios no es un artefacto del final del entrenamiento, sino que se acumula y crece de manera constante a lo largo de todo el proceso de aprendizaje.
Estos resultados sugieren que la estructura topográfica actúa como un sesgo inductivo (inductive bias) superior. En el aprendizaje automático, un sesgo inductivo es un conjunto de suposiciones que un algoritmo utiliza para generalizar. Un modelo con un sesgo inductivo débil, como los de conectividad aleatoria, parte de pocas suposiciones. En contraste, el modelo topográfico incorpora un sesgo inductivo fuerte y bien fundamentado, heredado de millones de años de evolución: la suposición de que las características relacionadas (como los píxeles adyacentes en una imagen) deben procesarse juntas en las primeras etapas. Los resultados empíricos demuestran que este sesgo, lejos de ser una restricción, proporciona un “andamiaje” mucho más efectivo para el aprendizaje, guiando a la red hacia soluciones más robustas y de mayor rendimiento de manera más eficiente que un punto de partida aleatorio y desinformado.
Sección 7: Conclusión: Un Retorno a los Principios Biológicos para una IA Sostenible
La investigación sobre el Mapeo Topográfico Disperso (TSM) y su versión mejorada (ETSM) representa más que el desarrollo de un nuevo algoritmo. Constituye un argumento elocuente para un cambio de paradigma en el diseño de la inteligencia artificial, un retorno a la elegancia y eficiencia de los principios biológicos que Cajal comenzó a desvelar. Al sintetizar los hallazgos de este trabajo, emerge una visión clara de una IA más sostenible, potente y, en última instancia, más alineada con la inteligencia que busca emular.
Una Solución Probada para la Crisis de Sostenibilidad
Este informe comenzó delineando la creciente crisis de sostenibilidad que enfrenta la IA. El marco ETSM se presenta como una solución práctica y de alto rendimiento a este desafío. Los resultados empíricos demuestran de manera concluyente que es posible reducir drásticamente el impacto ambiental de la IA sin comprometer, y en algunos casos incluso mejorando, su rendimiento. Con reducciones de consumo energético que superan el 99%, ETSM ofrece un camino tangible hacia la “Green AI”, alineando el avance tecnológico con la responsabilidad ecológica.
Rompiendo el Falso Compromiso entre Precisión y Eficiencia
Durante años, se ha asumido un compromiso inevitable entre la precisión de un modelo y su eficiencia. Los hallazgos de este estudio rompen decisivamente con este dogma. Al lograr una precisión superior a la de los modelos densos en tareas complejas y al mantener un rendimiento de vanguardia con niveles de dispersión de hasta el 99%, ETSM redefine lo que es posible en el aprendizaje profundo eficiente. Demuestra que la dispersión, cuando se implementa de manera inteligente y estructurada, no es una mera compresión, sino una poderosa herramienta de regularización.
Implicaciones Más Amplias y la Visión de Futuro
Las implicaciones de este trabajo se extienden mucho más allá del laboratorio. La drástica reducción en la huella de memoria y los requisitos computacionales abre la puerta al despliegue de modelos de IA potentes en dispositivos de borde, catalizando una nueva ola de aplicaciones inteligentes y descentralizadas. Al mismo tiempo, al reducir significativamente los costes de entrenamiento, este enfoque contribuye a democratizar la investigación en IA, permitiendo que más mentes participen en el desarrollo de tecnologías de vanguardia.
El propio estudio señala varias líneas prometedoras para futuras investigaciones:
-
Extensión a Capas Profundas: Extender esta inicialización estructurada a las capas más profundas de la red podría conducir a redes aún más eficientes desde su concepción.
-
Aplicación a Nuevas Arquitecturas: La aplicación de TSM/ETSM a las capas de Redes Neuronales Convolucionales (CNN) y Transformers es un paso lógico y prometedor que podría generar enormes ahorros de eficiencia en los modelos más utilizados hoy en día.
Esta investigación, liderada por Mohsen Kamelian Rad, Ferrante Neri, Sotiris Moschoyiannis y Roman Bauer, fue publicada en la revista Neurocomputing bajo el título “Topographical sparse mapping: A neuro-inspired sparse training framework for deep learning models” (DOI: 10.1016/j.neucom.2025.131740).
En última instancia, el Mapeo Topográfico Disperso no debe ser visto simplemente como un algoritmo, sino como la demostración de una filosofía de diseño más profunda. Es un testimonio del poder de mirar a la naturaleza, no en busca de una metáfora superficial, sino de principios de ingeniería probados por el tiempo. Al emular la conectividad estructurada, dispersa y eficiente del cerebro —los mismos principios que los dibujos de Cajal revelaron al mundo—, la inteligencia artificial puede encontrar un camino para resolver sus desafíos más apremiantes y construir un futuro donde la inteligencia, tanto artificial como natural, pueda prosperar de manera sostenible.
Topographical sparse mapping: A neuro-inspired sparse training framework for deep learning modelsDescarga


Comentarios
Para activar los comentarios: ve a giscus.app, introduce el repositorio
joseadserias-dotcom/cajal-digitaly reemplaza los IDs ensrc/layouts/Articulo.astro.